Data Science Glossary
Common Data Elements (CDE): CDEs are standardized, narrowly defined questions that pair with a set of specific allowable responses. They can be used across different sites, research studies, or clinical trials to ensure consistent data collection.
Container: A standard unit of software that packages up code and all its dependencies, so the application runs quickly and reliably from one computing environment to another.
Dashboard: A dashboard is a visual display of data. A dashboard usually sits on its own page and receives information from a linked database.
Data cleaning: The process of detecting and correcting or removing corrupt or inaccurate records from a data set.
Data dictionary: A collection of descriptions of the data objects or items in a dataset. A data dictionary is used to catalog and communicate the structure and content of data and provides meaningful descriptions for individually named data objects.
Data integration: Combining diverse datasets from disparate sources into one unified dataset or database. Data are accessed and extracted, moved, validated, cleaned, transformed, and loaded.
Data management: The development, execution, and supervision of (research) plans, policies, programs and practices that control, protect, deliver, and enhance the value of (research) data and information assets.
Data repository: A place that holds data, makes data available to use, and organizes data in a logical manner. A data repository may also be defined as an appropriate, subject-specific location where researchers can submit their data. Data repositories are typically classified as domain specific, generalist, and institutional.
Data sharing: The practice of making data, including metadata, and additional data documentation (e.g., on methods, techniques, and procedures) that allow data to be correctly interpreted, available to others for scholarly research.
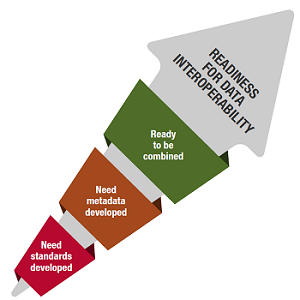
Data standards: Data standards are documented agreements on representation, format, definition, structuring, manipulation, use, and management of data. Data standards are needed for data to be presented and exchanged.
Database: A collection of data that is organized according to a conceptual structure/model describing the characteristics of these data and the relationships among their corresponding entities, supporting one or more application areas.
Dataset: A dataset is a collection of scientific data including primary data and metadata organized and formatted for a particular purpose.
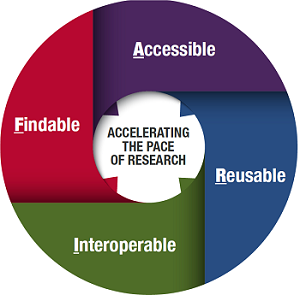
FAIR: FAIR data are data which meet the principles of findability, accessibility, interoperability, and reusability.
- Findability: The first step in (re)using data is to find the data. Metadata and data should be easy for other users to find.
- Accessibility: Once the user finds data they want to use, they need to know if and how they can be accessed, possibly including authentication and authorization.
- Interoperability: The capability to communicate, execute programs, or transfer/combine data in a useful and meaningful way that requires the user to have little or no knowledge of the unique characteristics of those units.
- Reusability: Data reuse by other users is an important facet of the research process that enables the verification and replication of results, minimizes duplicate work, and builds on the work of others.
Metadata: Metadata are structured, descriptive information of primary data and answer the five W-questions: What has been measured, by Whom, When, Where, and Why?
Ontology: An ontology is an organization and description of concepts within a particular domain that includes hierarchical relationships between objects. Every academic discipline or field creates ontologies to limit complexity and organize data into information and knowledge. At a minimum, ontologies are controlled, structured vocabularies.
Open science: Open science aims to make scientific research, data, and their dissemination available to any member of an inquiring society, from professionals to citizens. It encompasses practices such as publishing research and making data accessible to the public to make it easier to publish and communicate scientific knowledge.
Primary Data: Primary data are scientific raw data. They are the result of scientific experiments, observations, or simulations, and vary in type, format, and size.
Schema: A metadata standard for labeling, tagging, or coding for recording and cataloging or structuring data. records.
Secondary Data: Secondary data are data that have already been collected and are readily available from other sources. They can also refer to data that a researcher has not collected or created themselves.